DNA Synthesis
DNA Synthesis Vector Selection
Vector Selection Molecular Biology
Molecular Biology Oligo Synthesis
Oligo Synthesis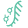 RNA Synthesis
RNA Synthesis Variant Libraries
Variant Libraries Genome KO Library
Genome KO Library Oligo Pools
Oligo Pools Virus Packaging
Virus Packaging Gene Editing
Gene Editing Protein Expression
Protein Expression Antibody Services
Antibody Services Peptide Services
Peptide Services DNA Data Storage
DNA Data Storage Standard Oligo
Standard Oligo Standard Genome KO Libraries
Standard Genome KO Libraries Standard Genome Editing Plasmid
Standard Genome Editing Plasmid ProXpress
ProXpress Protein Products
Protein Products
Since Köhler and Milstein's landmark invention of hybridoma technology in 1975, hybridoma cell lines have served as the cornerstone of monoclonal antibody (mAb) production. Yet possession of a cell line alone is no longer sufficient. Obtaining the precise nucleotide sequence encoding the antibody's variable regions — hybridoma sequencing — has become an indispensable prerequisite for recombinant expression, humanization, intellectual property protection, and antibody engineering. This article reviews the genomic complexity of hybridoma cells, the major sequencing strategies, critical success factors, and the downstream applications that sequence knowledge enables.
1. Why Sequence Your Hybridoma?
Hybridoma cell lines are inherently unstable biological resources. Extended passaging can cause chromosomal loss, somatic mutations, or silencing of antibody secretion. Cryostocks are vulnerable to equipment failure and institutional changes. Most critically, a physical cell line cannot anchor patent claims, recombinant production, or rational engineering.
Hybridoma sequencing addresses all of these vulnerabilities by recovering the nucleotide and amino acid sequences of the antibody heavy chain variable region (VH) and light chain variable region (VL) — including the three complementarity-determining regions (CDR1–CDR3) responsible for antigen contact. As DuBois & López noted (PLOS ONE, 2019), knowledge of variable region sequences and subsequent recombinant expression directly reduces the impact of hybridoma cell loss and instability.
2. The Genomic Complexity of Hybridoma Cells
Sequencing a hybridoma is more demanding than sequencing a typical cDNA target for three reasons.
Myeloma background transcripts. Common fusion partners (SP2/0-Ag14, P3X63Ag8.653, NS0) retain transcriptionally active, non-productive immunoglobulin loci. Total RNA therefore contains both the target antibody mRNA and non-functional myeloma-derived transcripts that can co-amplify and produce ambiguous results.
Light chain isotype ambiguity. Murine antibodies carry either κ or λ light chains. Since the isotype is not always known in advance, protocols must include reactions for both, followed by functional verification of the correct pair.
IgG subclass diversity. The four murine IgG subclasses (IgG1, IgG2a, IgG2b, IgG3) have partially distinct framework sequences. Constant-region primers must match the correct subclass; isotype misidentification is a common and underappreciated source of failure.
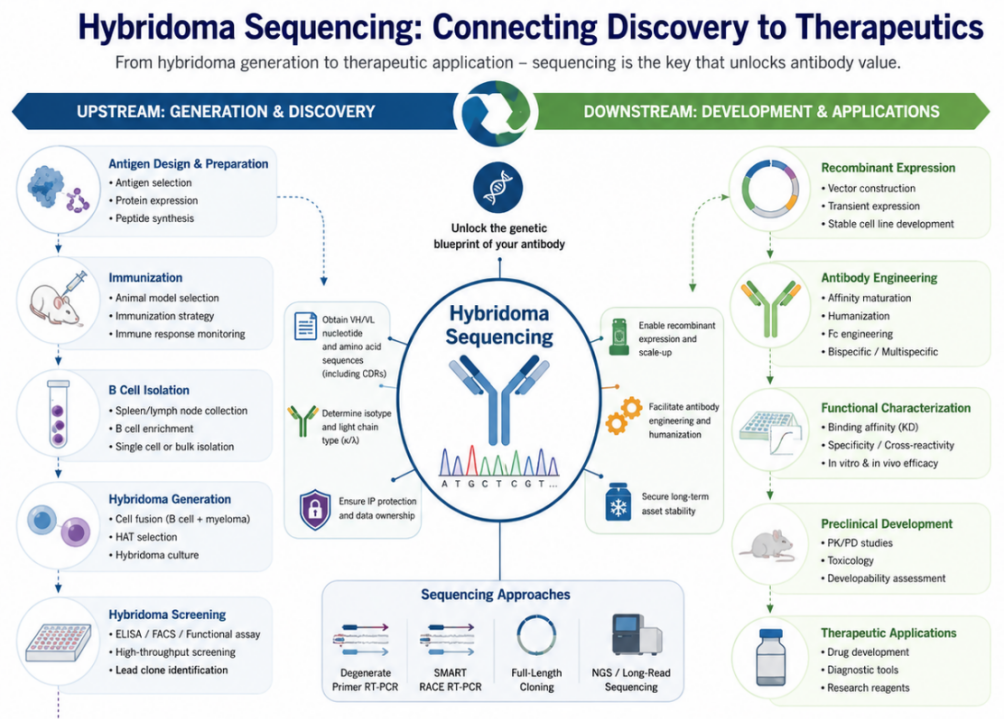
Figure 1. Overview of the hybridoma sequencing ecosystem and its upstream and downstream applications.
3. Major Sequencing Strategies
3.1 Degenerate Primer RT-PCR
The classic approach uses mixed degenerate primers to amplify variable regions from hybridoma cDNA, followed by Sanger sequencing of the gel-purified product. It is low-cost and technically accessible, but risks preferential amplification of certain framework sequences and is especially prone to myeloma background co-amplification, since degenerate primers cannot discriminate productive from non-productive transcripts.
3.2 Template-Switch RT-PCR (SMART Technology)
The most widely adopted modern method exploits the intrinsic template-switching activity of MMLV reverse transcriptase, as described by DuBois & López (PLOS ONE, 2019). Rather than priming from the variable region, reverse transcription begins within the highly conserved constant region, eliminating any dependence on prior VH/VL sequence knowledge.
The mechanism proceeds in four steps: (1) a constant-region-specific primer initiates reverse transcription toward the 5' mRNA cap; (2) MMLV reverse transcriptase appends a non-templated poly-C overhang upon reaching the cap; (3) a template-switch oligonucleotide (TSO) with a poly-G tail anneals and the enzyme switches templates, adding a defined adapter sequence; (4) PCR with an adapter-specific forward primer and a nested constant-region reverse primer amplifies the complete variable region — no degenerate primers required.
Figure 2. Schematic of the SMART template-switch RT-PCR workflow. Steps 1–4 show constant-region-primed reverse transcription, non-templated poly-C addition, TSO annealing, and final PCR amplification.
Three reactions are set up per hybridoma (κ chain, λ chain, heavy chain). The approach is robust across all IgG subclasses and light chain isotypes, with a turnaround of approximately five days.
3.3 Full-Length Two-Step Workflow
Konthur (Antibodies, 2025) extended variable-region sequencing to a complete full-length cloning strategy. In Step 1, variable regions are amplified, cloned, and Sanger-sequenced; consensus sequences are annotated with IgBLAST, and the IgG subclass is determined from CH1 isotype-specific motifs — no commercial isotype strips needed. In Step 2, CDR3-specific primers are designed to amplify the full constant regions, yielding complete heavy and light chain coding sequences ready for expression vector construction.
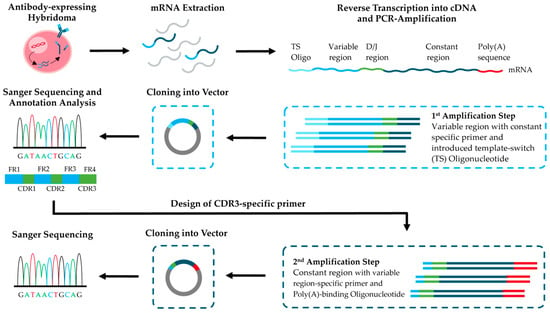
Figure 3. Two-step workflow for full-length hybridoma antibody sequencing and cloning.
3.4 NGS and Long-Read Nanopore Sequencing
For large hybridoma collections or incompletely cloned populations, NGS amplicon sequencing offers high throughput and effective discrimination of target from myeloma background sequences based on read frequency. For same-day full-length sequencing without cloning, Oxford Nanopore long-read sequencing (NAb-seq; Pabst et al.,Frontiers in Immunology, 2022) generates V(D)J annotation and CDR3 sequences from ~0.5 million reads in under 24 hours.
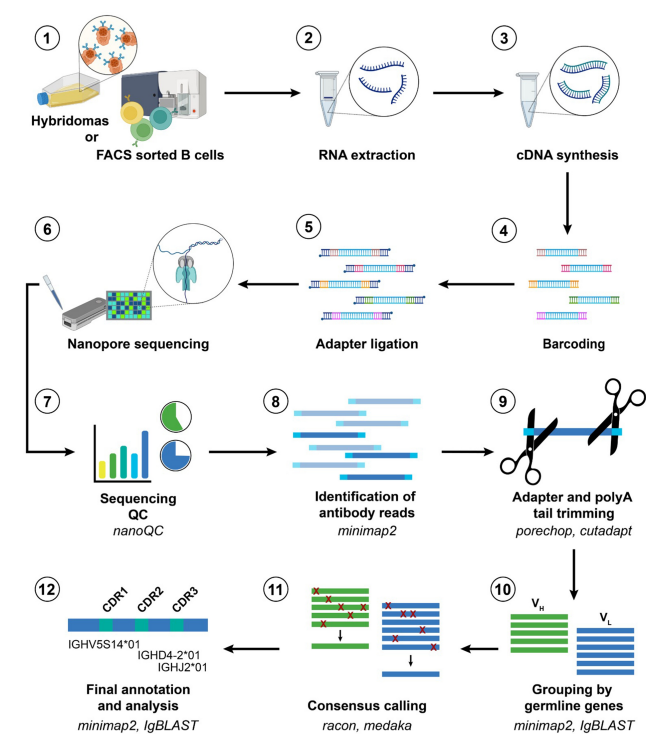
Figure 4. NAb-seq workflow using Oxford Nanopore long-read technology, from RNA extraction through bioinformatic V(D)J annotation.
4. Keys to Sequencing Success
Monoclonal purity is the single most critical prerequisite. At least two rounds of limiting dilution cloning with ELISA confirmation should precede sequencing; mixed populations generate unresolvable trace overlaps.
RNA quality must be verified before proceeding. Spectrophotometry (A260/A280 ≥ 1.8) and capillary electrophoresis (RIN ≥ 7) are the minimum quality checks. Samples should be processed on ice and stored at −80°C.
Reverse transcriptase and polymerase selection matter. MMLV-derived enzymes with low RNase H activity (SuperScript IV, RevertAid) maximize full-length cDNA yield. High-fidelity polymerases (Phusion, Q5) minimize artifactual mutations in the 350–500 bp variable region amplicon.
Clone depth for Sanger sequencing. Sequencing 8–16 independent clones per chain allows confident distinction of the functional antibody sequence from lower-frequency myeloma background sequences.
5. Downstream Applications
Hybridoma sequencing is not an end in itself — it is the gateway to the full scope of modern antibody science:
• Recombinant expression in CHO or HEK293 cells, independent of hybridoma survival
• Antibody humanization via CDR grafting onto human framework regions
• Intellectual property protection through sequence-anchored composition-of-matter patents
• Antibody engineering: bispecific formats, ADC conjugation, Fc optimization, scFv/nanobody construction
• Research reproducibility: sequence-defined antibodies meet the emerging standards of major journals and funders (Bradbury & Plückthun,Nature, 2015)
6. Hybridoma Sequencing Services at Synbio Technologies
At Synbio Technologies, we offer a comprehensiveHybridoma Antibody Sequencing service as part of our integrated antibody solutions platform. Leveraging both Sanger sequencing and NGS approaches, our team delivers accurate VH and VL variable region sequences — including full CDR annotation and IMGT-based analysis — directly from your hybridoma cell lines. Whether your starting material is a well-established frozen stock or a freshly subcloned culture, our end-to-end workflow is designed to provide high-confidence sequence data with rapid turnaround, protecting your research investment and laying the molecular groundwork for all downstream applications.
Beyond sequencing, Synbio Technologies operates as a true one-stop synthetic biology partner. Once your antibody sequence is in hand, our team can seamlessly support the full continuum of antibody development — from antibody gene synthesis and recombinant antibody production to antibody humanization, affinity maturation, and stable cell line construction. This integrated capability means that a hybridoma cell line on your bench today can become a fully characterized, recombinantly expressed, and engineered therapeutic candidate without ever leaving our platform. To learn more or to submit your project, please visit our Hybridoma Antibody Sequencing service page or contact us directly.
References
1. Köhler, G. & Milstein, C. (1975). Nature, 256, 495–497. https://doi.org/10.1038/256495a0
2. DuBois, R.M. & López, A. (2019). PLOS ONE, 14(6), e0218717. https://doi.org/10.1371/journal.pone.0218717
3. Konthur, Z. (2025). Antibodies, 14(3), 72. https://doi.org/10.3390/antib14030072
4. Pabst, M. et al. (2022). Frontiers in Immunology, 13, 931362. https://doi.org/10.3389/fimmu.2022.931362
5. Bhatt, D.L. et al. (2023). Nature Communications. https://doi.org/10.1038/s41467-023-41550-w
6. Bradbury, A.R.M. & Plückthun, A. (2015). Nature, 518, 27–29. https://doi.org/10.1038/518027a